In my blog I’m deliberately avoiding the question of why go global, since so much has already been said about this topic. Likely, the decision of whether or not to expand your software to international markets is already behind you, and you’re keen on reaching these 2.9 billion non-English-speaking users and tapping into international dollars (or rather – euros, yens, juans, rubles…).
Rather than why go global, I’m often faced with the question of what internationalization actually is, and why would a software company even bother about it. Is it possible to enter international markets without doing your internationalization homework? What are the consequences (if any)?
If you speak a second language, you might already have some experience with poorly localized apps – where issues like cut-off UI text, random untranslated words, garbled fonts, or ridiculous mistranslations, have a dramatic effect on user experience, and it’s literally impossible not to notice these bugs. However, if English is your first language, you might have little to no exposure to such issues since most software is developed for English-speaking markets (and thus free of internationalization bugs in English language version). To better understand gravity of the problem, let me show you some examples of what happens to software released to international markets without correct internationalization work…
Truncated UI text
One of the most common issues in localized apps where no proper internationalization has been done, concerns truncated translations – or simply – cut off text in the UI. In a typical case, engineers, designers, and product managers all work together to create beautiful UX for English-speaking users, assuming the UX is going to be the same for international users after translation. Well, it’s not… A perfect UI designed for a single language is going to look ugly after translation. Words across languages vary in length and most locales simply need extra UI space to fit more characters. German and Turkish are typical “offenders”, but realistically, if you localize your software into any 5 additional languages, it’s almost certain some translated words are going to overflow the UI. The result is poor user experience or even crippled product functionality. Here are a few examples:

Second word cut off in French UI.
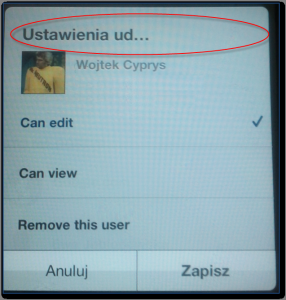
Unfortunate ellipsis in this Polish UI. Cut off translation says “thighs settings” instead of “sharing settings”.

Ellipsis disrupts app functionality. UI labels are not clear.
There is no one-fits-all solution for the text expansion problem. One good practice that can save you many headaches with truncated translations is to allocate at least 30% more UI space for text expansion. This way translations can grow as needed, and you avoid numerous UI redesigns later on. Note that some very short UI strings, like ‘Done’, ‘Save’, ‘Up’ or ‘Go’, can expand even by 200-300% in translation, so it’s also recommended to avoid crammed UI designs, keeping in mind the text growth in other languages.
And if you’re not sure whether your current UI has enough space for translations, there are handy pseudolocalization tools out there that instantly create mock translations for your UI by appending random diacritics and a few additional characters to each English text string – for example like this: ïñƭèřñáƭïôñáℓïƺáƭïôñ ℓôřè₥. This way you can test your UI for text expansion and see what is likely going to break when you upload real translations into your app. You can find ready-made pseudolocalizers in GitHub, e.g. this one for .NET, or create your own. Manual, web versions like pseudolocalize.com are also available for small-scale testing.
Confusing Date & Time Format
If your software includes any date pickers or calendar widgets, then you should worry about displaying the date according to target user’s locale (preference). It’s not only about translating month names or abbreviations for weekdays, but also showing them in the right order (DD-MM-YYYY or MM-DD-YYYY or YYYY-MM-DD etc.), natural for the user. What is more, a typical calendar week in the United States starts on Sunday, while for most other countries it’s Monday. A small detail, but it is likely to mislead or confuse the user if not adjusted to target locale. Basically, never assume the notation of time, date, timezones, numbers, currencies etc. is universal across international markets. While they vary per market, such notations are well-defined, and codified in open source i18n libraries, e.g. ICU based on CLDR standard from Unicode. It’s just a matter of using these libraries in your code, rather than trying to reinvent the wheel… And believe me, you don’t want to spend time coding date formats for each country.
Here is a great example of a properly internationalized date picker (note the differences in date format and last day of the week):

Issues with Fonts
It’s hard to spot issues with fonts in your localized app until you can actually read the target language. To an English-speaking engineer fonts may appear fine after translation, but there are a number of issues typically affecting legibility of fonts, especially in non-Latin languages. First of all, accented characters may be missing or distorted:

Accented characters appear in different (somewhat bolded) font.
…and in some cases simply do not fit in the allocated UI space:

Accents are cut off above capital letters.
An untrained eye won’t notice the issue, but target users might not be able to understand the text or get confused by garbled characters.
Non-latin scripts, especially Asian, often require a few more pixels of height to fit entire characters. Compare these two sentences in English and Thai – two rows of text, but Thai characters are nearly 50% taller:

Asian scripts also pose a challenge with some characters being illegible (or hard to read) if displayed in too small font:

While font issues can ruin UX across the entire app, they usually stem from a single root cause, namely, font type used does not support all the new languages you’ve added to your app. You might need to use a more universal font, supporting more languages, or select different font types for groups of locales, e.g. Noto Serif CJK for East Asian languages, etc.
Hardcoded locale-specific strings
A very common issue in incorrectly internationalized software is that with multiple hardcoded strings in the code. Each hardcoded string is going to appear to users as untranslated text across all language versions of the app. As a remedy, make sure all your engineers use string resources as a reference for text strings, e.g.:

Strings concatenation
The last i18n issue I’d like to mention stems from the fact engineers sometimes have too much love for simple (and elegant) solutions in their code. Like re-using existing text objects to form new, compound UI elements. But building a new sentence out of existing textual building blocks is going to open a world of internationalization issues in a localized app… See this old Gmail UI with a “neatly” crafted English sentence out of four (!) separate text strings:

It works great in English, but it won’t work in most other languages, resulting in either awkward translation (poor UX) or completely unintelligible sentence (reduced functionality). Languages differ in word order, sentence structure, pluralization rules, and so on, so make sure to include each individual logical unit (a sentence, a standalone phrase) in a separate string. Your translators are going to thank you for that as well, saving time to guess what is being followed by “Forward a copy of incoming mail to…” – a name, an email address, an inbox, or perhaps another phrase?
I’ve mentioned just a few examples of typical issues your software is going to suffer from if you’ve not done your internationalization homework and took a shortcut expanding to international markets. Even a couple of such engineering & design issues can result in a great number of user-facing eye-sores, leading to poor user experience, and consequently lower product adoption in global markets. Paradoxically, product managers often underestimate the impact localization can have on overall user satisfaction and product adoption. Poor language experience in an app can kill its functionality, and even the best product features are going to be crippled if users are confused how to use them or put off by sloppy, unprofessional language.
Happy internationalizing!